git checkout -b git-primer

git init
MOTIVATION FOR THIS TALK
- Explain the common git vocabulary
- Empower our team to be confident using git
- Demystify git's usage

SURVEY RESULTS
WHAT DID YOU GET YOURSELF INTO?
- Review what a version control system (VCS) is
- A simple GIT end-to-end lifecycle
- Common GIT usage & corresponding gotchas
WHY USE A VCS?
- File state management
- Sharing & Collaboration
- Parallelize a team's workflow
WHAT'S GIT
- A flexible version control system
- Written by Linus Torvalds in 2005
- Open Source / Community Driven
- A Distributed or Decentralized VCS
CENTRALIZED VCS
SVN Style
- The project repository is the sacred source of truth
- Everything usually pushed to the trunk of the repo
- Single point of failure
- There's only one copy of the code
- Hard to work without access to the server
- Must always address conflicts before pushing
HOW IT WORKS!
CLONE A REMOTE REPOSITORY
$ svn checkout svn+ssh://svn@example.com/svn/trunkINSPECT THE HISTORY
$ svn log | lessCOMMIT SOME LOCAL CHANGES
$ svn add <file>
$ svn rm <file>PUSH CHANGES TO THE REMOTE
$ svn commit -m 'message'DECENTRALIZED VCS
GIT Style
- Multiple workflows can easily be supported
- No single point of failure
- Each developer has a full backup of the main server
- Easily begin work with no internet/server access
- The full project source can be pushed anywhere
HOW IT WORKS!
CLONE A REMOTE REPOSITORY
$ git clone ssh://git@example.com/path/to/git-repo.gitINSPECT THE HISTORY
$ git logCOMMIT SOME LOCAL CHANGES
$ git add <file>
$ git rm <file>
$ git commit -m 'message'PUSH CHANGES TO THE REMOTE
$ git pushWait a minute...
This looks a lot like SVN!!

YOU'RE RIGHT!


sort of...
A QUICK COMPARISON
SVN
$ svn add <file | directory | etc>
$ svn commit -m 'message'svn add
schedules files, directories, or symbolic links in your working copy for addition to the repository
svn commit
send your changes from the working copy to the repository
GIT
$ git add <file | directory | etc>
$ git commit -m 'message'
$ git pushgit add
updates the [staging area] using the current content found in the working tree, to prepare the content staged for the next commit
git commit
stores the current contents of the [staging area] in a new commit ... describing the changes
git push
Updates remote refs using local refs, while sending objects necessary to complete the given refs.
REVIEW
- svn add and git add both stage files for sending to the remote
- git commit is used to bundle the changes from git add into a lightweight snapshot
- svn commit and git push both send the staged files to the remote
GIT has an extra step, why would we use this garbage?
BECAUSE...
- Cheap, local branching can't be understated
- GIT is fast
- All commands can be run locally with no internet connection until you push back upstream.
- You get the full project history in the same time it takes to fetch an SVN version.
- Having repository issues? Have anyone on the team push the full project somewhere else within minutes.
- Branches in GIT are not a dirty word like SVN
- GIT's staging area allows you to group files together logically and bundle them in a commit.
THE TENETS OF GIT

COMMIT OFTEN
- Commits are cheap & fast snapshots to points in time
- There is no danger in committing often
- You can always change commit histories locally at a later time using rebase
BRANCH OFTEN
- A branch is a lightweight, movable pointer to a specific commit hash
- Context switching is frictionless due to commits, branches & stashes
- Disposable experimentation is encouraged because branching allows you to write code quickly outside of your main code flow
SIMPLE GIT LIFECYCLE

BEGIN A NEW GIT PROJECT
$ cd path/to/where/you/want/to/start
$ git initUse a remote repo for collaboration
$ git remote add origin https://example.com/path/to/git/repo.gitOPTIONAL
DOWNLOAD AN EXISTING GIT PROJECT
$ git clone ssh://git@example.com/path/to/git-repo.gitOR
TL;DR:
Every git project has a hidden folder called .git containing everything git needs to track your project
$ git status
TL;DR:
Git status is your go-to command to see the state of the files in your project
FILE STATUSES
- Untracked
- changes to these files are not recorded by GIT
- Tracked
- Unmodified: No changes were made
- Modified: These files have been modified since the last commit
- Staged: Modified and ready for a new commit to take place
TRACKING FILES
$ git addTL;DR
When you git add files, they're added to a special place called the staging area
touch README.md
git status
git status
git add README.md
git status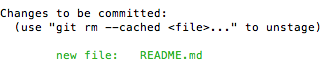
TRACK THE NEW FILE
PROTIP:
// stage all files for commit
git add .
OR
git add -A$ git commitTL;DR:
git commit takes a snapshot of the state of your files
COMMIT THE CHANGES
git commit -m 'added README file to the project'
git status
COMMIT PROTIP:
// use the -am flags to stage and commit all TRACKED files
git commit -am 'message'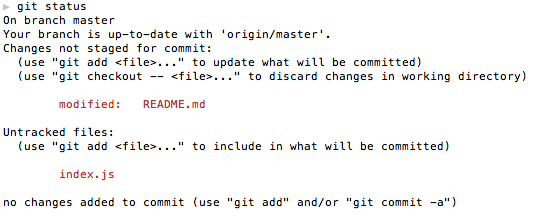
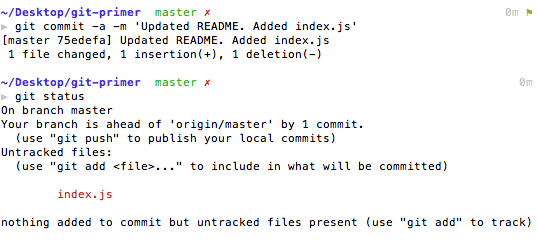
EXAMPLE:
LET'S FIX OUR COMMIT
but first....
$ git logTL;DR:
Use log to see the full commit history of the current branch
LET'S FIX OUR COMMIT
$ git commit --amend$ git log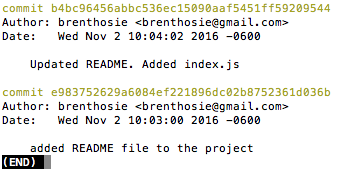
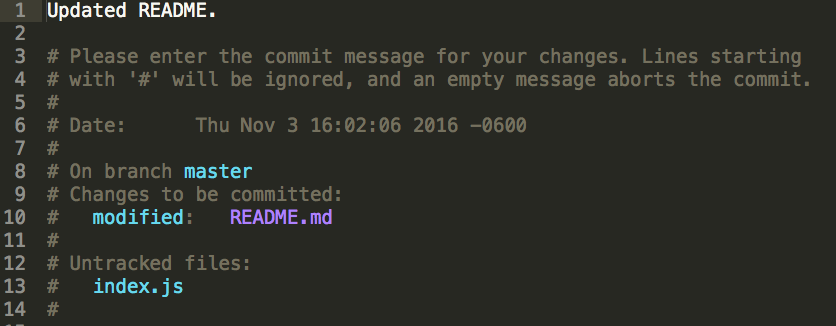
AFTER AMENDING THE COMMIT
$ git log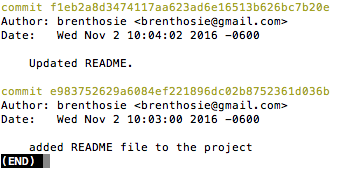
$ git status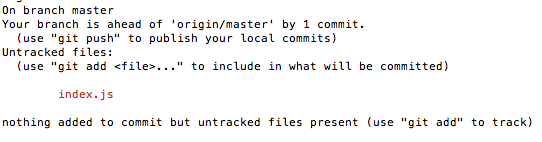
$ git pushTL;DR:
Use push to send your changes upstream to the remote
// push the branch to the remote
git push <remote> <branch-name>
// set the upstream link so you can run `git pull` with no arguments
git branch -u <remote>/<branch-name>PROTIP:
// push to the remote and set the upstream branch in one command
git push -u <remote> <branch-name>DO THE PUSH:
git push -u origin master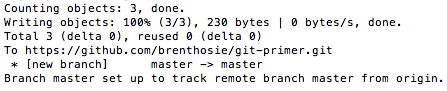
Usage
SIMPLE LIFECYCLE COMPLETE!

$ git rmTL;DR:
Use rm to stage the deletion and termination of tracking for the specified file
$ git rm <file>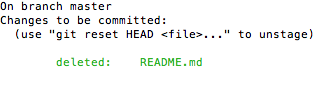
IGNORE FILES
$ EDITOR .gitignoreCOMMON GIT USAGE
BRANCHING
When do you branch?

BRANCHES ARE....
A lightweight, movable pointer to a specific commit hash
Local to your machine until you push them somewhere
A way to develop changes outside your main code flow

BY THE WAY
master is the default branch of every git project
(unless a narcissist deletes it)
BRANCHES SHOULD BE CREATED WHEN
- Starting a new feature
- You need to fix a bug
- You want to experiment
BASE BRANCHES ON
- Master
- If you are developing some feature or fix and Master gives you the best starting point
- Any other branch
- If there's code you need for this new feature, fix, or experiment that isn't in Master yet
LIST MY LOCAL BRANCHES
$ git branchLIST THE REMOTE BRANCHES
$ git branch -aCREATE A BRANCH
$ git branch <branch-name>CREATE NEW BRANCH, SWITCH TO IT
$ git checkout -b <branch-name>DELETE A BRANCH SAFELY
$ git branch -d <branch-name>DELETE A BRANCH WRECKLESSLY
$ git branch -D <branch-name>DELETE A REMOTE BRANCH
$ git push origin :<branch-name>HOW DO BRANCHES KNOW WHERE TO "POINT"?
-
Branches point to the latest commit
-
The latest commit is called the tip or HEAD of the branch
TL;DR:
Branching + Committing often lets developers defer synchronizing upstream until they’re at a convenient break point
GIT CHECKOUT
- Serves 3 distinct function:
- Check out files
- Checkout branches
- Check out commits
UNDO FILE CHANGES
$ git checkout <filename>CHECKOUT A BRANCH AT THE HEAD
$ git checkout <branch-name>CHECKOUT A COMMIT
AKA DETACHED HEAD STATE
$ git checkout <commit-hash>DETACHED HEAD STATE
- A safe, read-only snapshot of a previous version
- Allows you to inspect/run your code at a specific point in time
- HEAD now points to this specific commit hash
CREATING A NEW BRANCH FROM THE DETACHED HEAD
$ git checkout -b <some-new-branch-name>-
Save a quick reference to this commit as a branch
- Use it as a starting point for experimental code
REMINDER:
- Checkout serves 3 distinct function:
- Check out files
- Checkout branches
- Check out commits
GIT REBASE

IT'S REALLY NOT THAT BAD...
REBASE IS
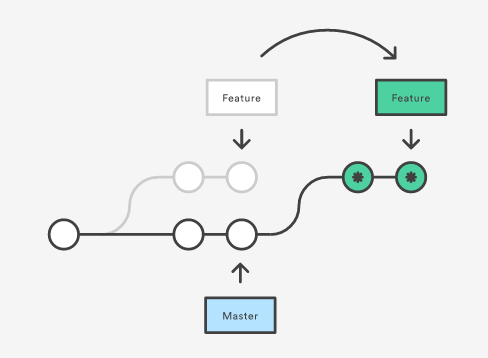
the process of moving a branch to a new base commit
REBASE IS PREFERRED BECAUSE...
- It creates a clean, linear history
- Merging creates a superfluous merge commit every time you go to incorporate changes from another branch
BEFORE REBASE
- git pull on the branch you are rebasing onto
- git push your latest changes to the remote for the branch you're rebasing
USAGE
$ git rebase <base><base> CAN BE ANY KIND OF COMMIT REFERENCE
(ID, BRANCH NAME, TAG, RELATIVE <HEAD> REFERENCE)
CAVEATS:
- Internally, GIT is creating new commits
- New commits mean that GIT is rewriting history
-
Never rebase public history that's on the remote repo
- More specifically, it's OK to rewrite history on the remote repo if no one else is basing commits off of your branch history
INTERACTIVE REBASE
USE INTERACTIVE REBASE TO
- Get all the benefits of a rebase, and...
- Gain complete control over what your commit history looks like
- Turn messy commits into cleaner, more well-thought-out chunks of work
- Squash insignificant commits
- Delete obsolete, obscure commits
- Split single commits into multiple commits
- Rewrite the actual comment on each commit
- Pretend like you knew what you were doing the first time.
- Commit like an idiot, rebase like a genius!
- Garrett Nay
CAVEATS CONT.
Rebasing a branch locally that is being tracked remotely leads to an interesting problem

Notice that the message here tells you to pull
WHAT GIT THINKS YOU SHOULD DO
$ git pullWHAT YOU SHOULD NOT DO
$ git pullWHY DOES GIT THINK YOU SHOULD PULL?
TL;DR: Collaboration Pushes vs History Rewrites
WHAT YOU SHOULD DO
$ git push --force origin <branch-name>$ git push --force-with-lease origin <branch-name>OR
WHAT'S HAPPENING?
- When you force push, you tell git "this is the new history chain"
- --force-with-lease will fail if someone else pushes changes to your branch. This gives you a chance to check out the situation before you obliterate the changes on the remote branch
TL;DR:
Never rebase commits or branches that other people have consumed/are consuming
CODE CONFLICTS
COMMON REASONS
- A developer deletes a file you made changes in
- Another developer edits the same area in the same file as you
- You and another developer create files of the exact same name in the same folder
WHEN CONFLICTS
CAN HAPPEN
- During a merge
- During a rebase
- There are others....
- cherry-pick, etc
DURING A REBASE
- Commits are "replayed" one after the other on top of each other
- When GIT encounters a conflict, it halts execution and tells you there are errors
- Use the status command in git to see the specific problem files

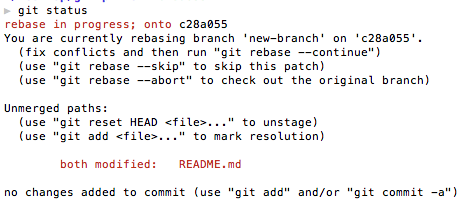
EXAMPLE
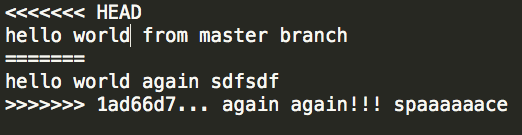
CONFLICT EXAMPLE
- Choose your merge strategy
- The base branch (master in this case)
- The current branch
- A mixture of the two
AFTER FIXING CONFLICTS
$ git add -A
$ git rebase --continueWHEN ALL COMMITS HAVE BEEN REPLAYED

FORCE PUSH!!
OPEN A PULL REQUEST
PROFIT!
TL;DR:
Conflicts are unavoidable, but they don't have to be scary
- confucius
(probably)
GIT REVERT
- A safe way to undo specific commits
- Preserves the old commit history
- Can be used to revert commits in the public repo
USAGE
// revert the latest commit of the current branch
$ git revert HEAD
// revert a specific commit from the history
$git revert <commit-hash>REVERT EXAMPLE
$ git log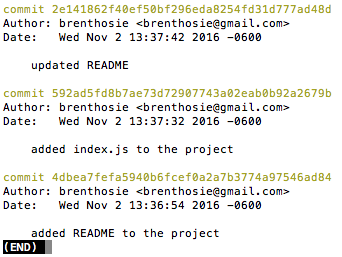
$ ls
$ git revert 592ad5fd8b7ae73d72907743a02eab0b92a2679b
$ git log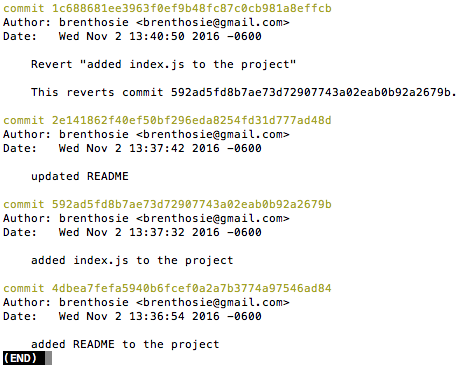
$ ls
TL;DR:
Use revert to get undo commits already consumed by the rest of the team
GIT RESET

GIT RESET
THE DANGEROUS UNDO
- The commits are no longer referenced by any ref or reflog
- These changes are permanent
- You may lose work
REMOVE FROM THE STAGING AREA, LEAVE YOUR CHANGES TO FILES.
$ git reset <file>RESET THE STAGING AREA TO MATCH THE MOST RECENT COMMIT. LEAVE YOUR CHANGES TO FILES. REBUILD THE COMMIT SNAPSHOT FROM SCRATCH.
$ git resetRESET THE STAGING AREA TO MATCH THE MOST RECENT COMMIT. OBLITERATES ALL UNCOMMITTED CHANGES.
$ git reset --hardMOVE THE CURRENT BRANCH TIP BACK TO <commit>.
LEAVE YOUR CHANGES TO FILES.
$ git reset <commit | HEAD>RESET THE STAGING AREA TO MATCH THE SPECIFIED <commit>. OBLITERATES ALL UNCOMMITTED CHANGES AND ANY CHANGES THAT OCCURRED AFTER THE SPECIFIED COMMIT.
$ git reset --hard <commit | HEAD>TL;DR:
- Use --hard for experiments that have gone horribly wrong.
- Never reset public commits in the remote repo

GIT TAGS
Tags in git are lightweight references that point to [the] SHA hash of a commit. Unlike branches, they are not mutable and once created should not be deleted
NON-ANNOTATED TAGS
- Points directly to a commit hash
- Meant for temporary or private labels
USAGE
// tag the latest commit
$ git tag <tag-name>// tag a specific commit
$ git tag <tag-name> <commit-hash>ANNOTATED TAGS
- Points to tag object that points to a commit
- Meant for during an actual release
USAGE
// tag the latest commit
$ git tag -a <tag-name> -m 'message'// tag a specific commit
$ git tag -a <tag-name> <commit-hash> -m 'message'PUSH TAGS
$ git push --tagsFETCH TAGS
$ git fetch --tags || git pullLIST TAGS
$ git tag -lDELETE A TAG
$ git tag -d <tag-name>
$ git push origin :refs/tags/<tag-name>CHECKOUT A TAG
$ git checkout <tag-name>TL;DR:
Tags are easily referenced bookmarks to specific commits
FIN
